
Prev: Indexes and NaN values | Next: Data access in DataFrame
The 'DataFrame' object¶
- A DataFrame object is a multi-dimensional table-like data structure (similar to a multidimensional array) containing a labeled collection of columns, each of which can be a different value type (numeric, string, boolean, etc.).
Example¶
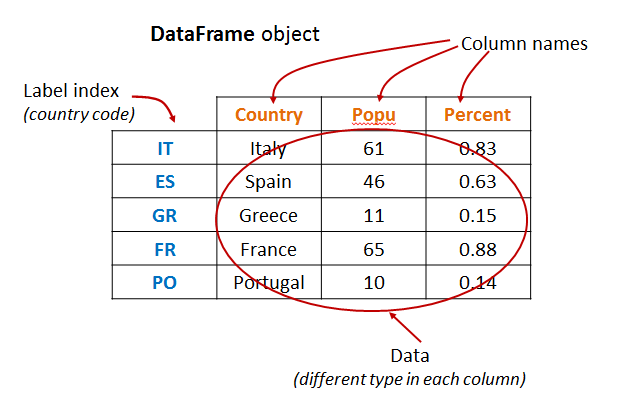
- Suppose that now your country data table includes additionally: (a) the full country name and (b) the percentage of world population that each country population corresponds to.
- Thus, for each country you have a row of data (instead of just a column entry as in a Series object).
- Suppose also that your country data are still label-indexed by the country two-letter code. The DataFrame object for this data representation would look like the following:
- Data for each country in rows
- Index labels (country code) for each country (row)
- Names for each column
(data for this table come from: Wikipedia: List of countries and dependencies by population)
Constructing a DataFrame object¶
- To better understand how to construct a DataFrame object consider the following first:
- The DataFrame has many rows and columns; each column can be thought of as a Series object and all columns (Series objects) share the same label indexes.
- As with the Series, the most convenient way to construct a DataFrame is from a dictionary with 'column_name:columns' as 'key:value' pairs. This dictionary is then passed as argument to the DataFrame constructor.
- Remember also that usually you will need to read data from an external file. Understanding, however, how to construct a DataFrame using a dictionary is useful as well.
In [1]:
import pandas as pd
data = {'country': ['Italy','Spain','Greece','France','Portugal'],
'popu': [61, 46, 11, 65, 10],
'percent': [0.83,0.63,0.15,0.88,0.14]}
df = pd.DataFrame(data, index=['ITA', 'ESP', 'GRC', 'FRA', 'PRT'])
print(df)
- Observe the way that the 'df' DataFrame is printed: columns do not necessarily appear in the order they were declared (of course, you can later change the column order as you like)
DataFrame from 'nested' dictionary¶
- If a nested dictionary is passed to DataFrame constructor, then:
- the outer dict keys will become columns and
- the inner keys will become the row indices
In [2]:
# Data are on unemployment percentage in GRC and ESP
import pandas as pd
un_data = {'GRC':{'2013':25, '2014':26, '2015':24.5},
'ESP':{'2013':23, '2014':27, '2015':26.5}}
df = pd.DataFrame(un_data)
df
Out[2]:
Loading data from external file¶
Import from xls, xlsx¶
- Use the read_excel() function to import data from xls/xlsx formatted file.
- In the following example, tha data refer to world countries population (source: "The World Bank")
- The 'sampledata.xls' file used is available here
In [3]:
import pandas as pd
df = pd.read_excel("../../data/sampledata.xls",sheetname="Data-8",\
skiprows=3, header=0, index_col=0)
df
Out[3]:
- We call the read_excel() mathod passing the following arguments:
- a) "../../data/sampledata.xls": the path and name of the data file (../../ denotes moving two levels above the folder where our code file is)
- b) sheetname="Data-8": give the name of the sheet we want to read (note that there are also other sheets in the xls file)
- c) skiprows=3: we skipped 3 rows in the beginning of the file that contain no data (check the xls file to see these rows)
- d) header=0: we defined as column names the first row after skipping (zero-indexed; in this case it would be the same even without setting the 'header' argument)
- e) _indexcol=0: finally, we define as label indexes the first (zero-indexed) column with country codes (if this was not set then new integer-based indexes would have been assigned - try it out in the code)
- Read more about read_excel() here
Import from csv¶
- In the following example we use the read_csv() function to read the same data from a csv formatted file
- A csv file is a file where data are separated with ',' as delimiter (csv = 'comma separated values')
- The 'sampledata.csv' file used is available here
In [4]:
import pandas as pd
df = pd.read_csv("../../data/sampledata.csv",sep=',',skiprows=3, header=0, index_col=0)
df
Out[4]:
As you can see we passed the same arguments and additionally sep=','
- Although it is not needed in this case, it is useful to know that you can explicitely state in read_csv() what the delimiter is. Assigning a delimiter value through 'sep' makes it easy to read data from csv files with various types of delimiters (for example ';').
Read more about the read_csv() function here

Copyright¶
 . Free learning material
. Free learning material
. See full copyright and disclaimer notice